
GitLab CI Pipeline for Eleventy
This post details the GitLab CI pipeline used for this blog, which is built with Eleventy. It's based on a collection of GitLab CI templates that have evolved over several years for my published NPM packages with a collection of end-to-end tests used for web applications and a few unique jobs added specifically for Eleventy and Nunjucks templates. It's meant as an illustration of a reasonably comprehensive CI pipeline for an Eleventy static site, maximizing the level of automated testing, leveraging built-in GitLab capabilities where practical, and optimizing parallelization and pipeline speed.
CI pipeline philosophy #
The following summarizes the general philosophy that I use for any CI pipeline. Some pieces are GitLab specific, but most are general platform independent recommendations based on my experience.
- The CI pipeline should execute all checks that are required to confirm that the application is in an acceptable configuration for deployment. This includes checking multiple configurations where applicable (for example light/dark mode, desktop/mobile configurations, OS/platform/framework versions).
- CI jobs should be deterministic, with job failure meaning a failure to execute properly or an unacceptable result that should not being deployed. There may be jobs with interpreted results (for example Lighthouse performance score changes, dependency vulnerabilities), but passing jobs should mean the results were successfully generated to be interpreted. Jobs that fail, but allow failure, resulting in the pipeline passing are a trap to be avoided. This can eventually leads to not reviewing the job results, assuming the failure cause is known, and the job failing for another reason goes unnoticed.
- Some might argue that CI pipelines should be highly optimized between what runs in a merge request and what runs on the primary branch. In general that is a mistake in GitLab CI. The GitLab merge request widgets are optimized to show changes since in the context of that merge request, for example, if you run a Code Quality report you only see the changes in that merge request, not all issues. If there is no reference job in the default branch, then the all results are identified as changes. Unless there are long-running jobs that need to be optimized or other specific drivers, there is benefit to running consistent pipelines.
- The pipeline should leverage built-in GitLab capabilities where appropriate. In this pipeline that includes analyses like code quality and some security related testing. There's no point in re-inventing the wheel unless there's a specific driver.
- The pipeline should be optimized to execute as many jobs as possible in parallel with clearly defined job dependencies, and should minimize repeating the same tasks in favor of performing them once and passing the artifacts as required.
- Jobs with external dependencies (for example dependency vulnerability scanning) should be run on a regular schedule, even with no commits to the repository.
- Deployment should be performed via an automated scripted process for consistency (even if manually initiated).
GitLab CI pipeline for Eleventy #
The complete CI pipeline for this site is shown below, ordered by execution sequence with job dependencies shown.
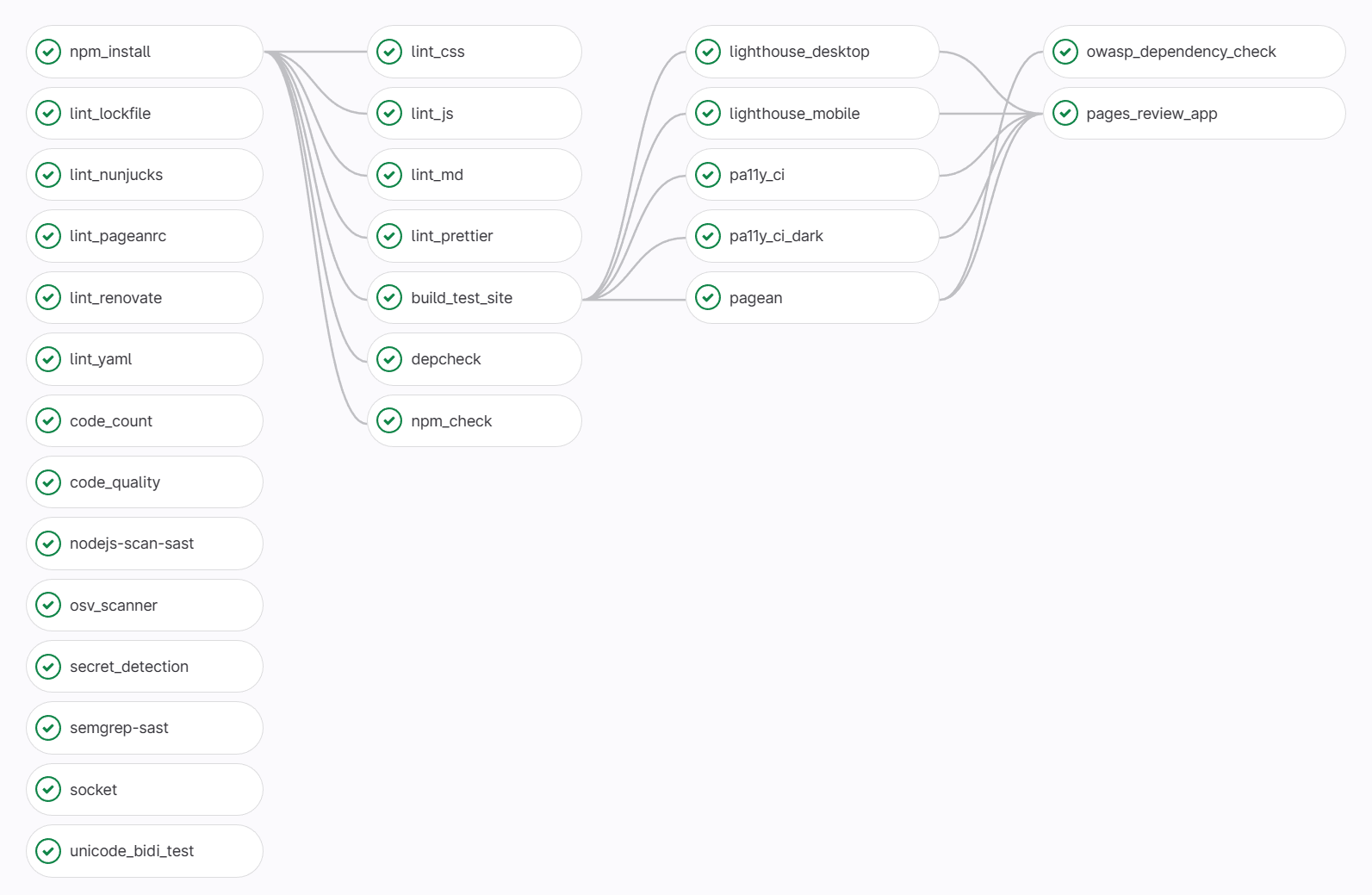
For efficiency, all jobs are defined with explicit needs, as can be seen in
the preceding example. This ensures that jobs start as early as possible, and
that only the artifacts required for the job are downloaded and extracted
(GitLab downloads the artifacts from all previous jobs unless otherwise
specified).
There are 28 jobs in the pipeline, which are grouped into the following functional categories:
- Installing Dependencies
- Language Specific Linting and Formatting
- Linting Tool Configuration Files
- Build Site
- Code Analysis
- End-to-End Testing
- Software Composition Analysis
- Static Application Security Testing
- Site Deployment
Installing dependencies #
The npm_install job installs all npm dependencies and saves then as artifacts.
This allows the install to be performed only once since it is an expensive
operation (in time and I/O) and the dependencies are then made available to any
subsequent jobs that require them.
Language specific linting and formatting #
Linting and format checking is performed for all languages used in this project. I use a very opinionated linting configurations for all tools to ensure consistency and maintainability throughout the codebase and to check for common issues. Development is done in a mix of VSCode and GitLab's WebIDE, so linting and formatting is not always checked there. When working VSCode, linting and format checking is performed is as a git pre-commit hook. The one place where linting and format checking is always performed is in CI.
The challenge with the pre-commit hook and CI cases is that the resulting logs are not reviewed unless there is an error. Operating this was for a long time on many projects has driven me to update all linting rule configurations to remove all warnings. Rules are either important enough to be errors or they're not and they're disabled. The errors then fail the pre-commit hook or CI pipeline. In some cases there are acceptable deviations, but these exceptions are then disabled in the code with the appropriate rationale.
The specific linting/formatting jobs and tools are detailed in the table below. Most of these are probably familiar names, other than maybe djLint. It's a Python tool for linting and formatting Nunjucks, Django, Handlebars, and many others. There's no other tool I've found in that space that comes close.
| Job | Tool |
|---|---|
lint_css |
stylelint |
lint_js |
eslint |
lint_md |
markdownlint |
lint_nunjucks |
djlint |
lint_prettier |
prettier |
lint_yaml |
yamllint |
Linting tool configuration files #
There are a few tools used by this project that offer linting tools to validate their configuration files. These jobs perform those checks to identify any formatting errors.
The lint_pageanrc job checks the
Pagean configuration file for validity.
See the End-to-End Testing section for more details on
Pagean. Formatting errors would also be found when running Pagean, but this
provides a job that explicitly identifies a configuration error, and this can be
run much earlier in the pipeline to fail fast if there is an issue.
The lint_renovate job checks the Renovate
configuration file for validity. Renovate is used by this project for automated
dependency updates, is quite powerful/configurable, and is highly recommended.
The Renovate process is run in another project, so an error in the Renovate
configuration would not otherwise be detected in this pipeline.
Build site #
The build_test_site job builds the site in a test configuration. This site
undergoes exhaustive end-to-end testing, so some production pieces are excluded
from the test build (for example analytics scripts), and the configuration sets
the pathPrefix to match the URLs used for that end-to-end testing.
Code analysis #
The pipeline includes a couple of general code analysis jobs that don't fall into one of the specific categories listed below.
The code_count job uses cloc to count
lines of code by language. This is primarily used to generate a
GitLab Metrics report,
which can then provide a change in code count by language in a merge request.
This is helpful as a check that an unexpected change wasn't accidentally
committed (for example if a new blog post was added, which should only be a
change in lines of markdown, but the lines of JavaScript changed as well, then
something is wrong).
The code_quality job run the
GitLab Code Quality
testing. The results for the entire project can be viewed, as can the
changes in a merge request.
End-to-end testing #
End-to-end testing, which involves analysis of the site in a browser, is performed to assess site performance, accessibility, and other quality control checks (for example no console errors, no broken links) as outlined below.
Lighthouse is run against one page
to get a representative set of data in both desktop (the lighthouse_desktop
job) and mobile (the lighthouse_mobile job) configurations. This data then
populates a
GitLab Metrics report,
which identifies any changes in Lighthouse scores in a merge request. See
this post
for more details on setting up Lighthouse and generating a metrics report.
Accessibility testing is performed using
Pa11y CI with both light mode (the
pa11y_ci job) and dark mode (the pa11y_ci_dark job) themes. Pally CI can be
configured to run with different accessibility test runners, and these jobs run
both the HTML_CodeSniffer and
Axe runners. There is also accessibility data
provided by Lighthouse, but the Pa11y CI results in general are more
comprehensive (especially when using both runners).
The pagean job run Pagean, a test
framework I started several years ago with a collection of tests intended to be
run against all pages in a site - broken links, errors written to the console,
horizontal scroll bar, page load time, and others. See
the documentation for complete details.
Software composition analysis #
Software Composition Analysis (SCA) involves a set of tools used to manage risks from a project's dependencies. This is a broad category that includes tools to catalog the project dependencies, check those dependencies for known vulnerabilities or other security risks, check for unused or deprecated dependencies, etc.
Two tools are used to check the project's dependencies for known
vulnerabilities. The owasp_dependency_check job runs
OWASP Dependency Check
against the project. This is a tool maintained by the OWASP foundation, and
checks not only package manifests like a lockfile, it also scans all files in
the project to check for any known vulnerabilities. This allows it to recognize
cases where dependencies are embedded and/or not identified, but also means the
scan is slower because it has to check every file in the project. It uses data
primarily from the U.S.
National Vulnerability Database (NVD), populated from
the Common Vulnerabilities and Exposures (CVE) database, the effective
international standard for identifying vulnerabilities. It also includes data
from other applicable vulnerability databases. The results not only identify any
known vulnerabilities, but also provide background on the vulnerabilities and
potential remediation steps.
The osv_scanner job runs OSV Scanner
to check for vulnerabilities identified in a lockfile or other package manifest.
It checks that listing of vulnerabilities against the
Open Source Vulnerabilities (OSV) Database, maintained by
Google. This includes data from multiple sources, but is focused on open source
vulnerabilities. Because it is using a defined listing of dependencies it runs
quickly. For this specific project, it is functionally no different than running
npm audit since the GitHub Advisories database is integrated into the OSV
Database, but this project leverages CI templates used for a variety of projects
in different languages, so this provides a broader solution.
OSV Scanner is currently undergoing testing here to determine if the data is reliable enough, and reported in a timely enough fashion, that it could replace
owasp_dependency_checkin projects where a listing of dependencies is available. So far that has not been shown to be the case. As this is being written, there is a new vulnerability identified by OWASP Dependency Check over a week ago that is still not reported in a GitHub Advisory, and therefore not by OSV Scanner.
Socket has taken a different approach than many other
tools in the area of dependency security to provide a detailed assessment of the
code for NPM (and other) packages to identify specific capabilities. For
example, it identifies that a package access files on disk, accesses the
network, spawns external processes, sends telemetry, and many other checks.
These actions are expected in some cases, but this provides the insight to
identify cases where it may not be. The socket job run the
Socket CLI for any merge requests
with dependency changes to assess any policy violations. At this point their
GitHub app is more mature, so this is
a recent addition still undergoing assessment to determine the best way to use
the results in GitLab. It's a tool worth taking a look at because it really does
provide the most comprehensive assessment of a package's codebase and potential
issues that I've seen.
The lint_lockfile job runs
npm-lockfile-lint to check that
packages in the lockfile are properly retrieved from acceptable sources. In this
case it ensures that packages are only pulled from NPM, over HTTPS, that the
integrity field has a SHA512 hash, and that the URL matches the package. This is
done to verify the integrity, fidelity, and vulnerability reporting for all
dependencies (with all of these settings configurable based on project needs).
The depcheck job runs depcheck to
identify any project dependencies that are not used or packages that are used
but are not dependencies. It does have some limitations, but finds references
for packages in .js/.ts files, in scripts running packages bin commands, or in
the configuration files of many major utilities (for example eslint, jest,
mocha, prettier).
The npm_check job run npm-check to
identify and packages with updates. While Renovate is used for automated
updates, this is a backup to identify cases where the Renovate job is failing to
make updates.
Static Application Security Testing #
Static Application Security Testing (SAST) tools analyze source code to find coding patterns that represent potential security issues. These analyses all focus on this project's code, not any project dependencies. Several SAST analysis tools are used, as outlined below.
The
GitLab SAST template
includes a series of language-specific SAST analysis tools, with rules
configured to run those applicable to your codebase. In this, with a
Node.js/JavaScript project that includes the nodejs-scan-sast and
semgrep-sast jobs.
The secret_detection job checks for any secrets (for example passwords, access
tokens/keys) committed to the git repository. This job is included from the
GitLab Security Detection template.
The unicode_bidi_test job runs
anti-trojan-source to
identify any bidirectional Unicode characters, which could be an indication of a
Trojan Source Attack.
Site deployment #
As noted in the preceding example, the build_test_site job builds the site in
a test configuration, so it must be rebuilt with the appropriate settings for
deployment.
The pages job runs only for commits to the default branch and builds the site
in the production configuration and deploys it to
GitLab Pages.
GitLab provides the capability to create a
review app with an instance of an
application with the changes in a merge request. Unfortunately, this capability
is not natively available for GitLab pages. To accomplish this, the
pages_review_app jobs run on merge request pipelines to leverage some
alternate GitLab capabilities to accomplish the same result. See
this post
for details on how to set up a GitLab review app for an Eleventy site.